Bfcache (Back-Forward Cache)
브라우저 페이지 이동 시 페이지의 상태를 완전히 캐싱해 사용자가 <뒤로가기(Back) | 앞으로가기(Forward)> 할때, 빠르게 로드할 수 있도록 하는 매커니즘
Bfcache는 페이지를 새로 로드하지 않고 캐시에서 복원하기 때문에 더 빠른 페이지를 탐색하게 하기 때문에 사용자 경험에 중요하다.
주요 특징
1. 전체 페이지 상태 저장
- DOM 상태, Javascript 메모리(힙 메모리 영역까지 포함), 스크롤 위치 등을 완전한 상태로 저장 (페이지를 메모리에 보관, = 스냅샷 보관)
- 새로 데이터를 요청하거나 렌더링하지 않고 (Javascript 재실행하지 않음) 이전 페이지의 상태를 그대로 복원
- 네트워크 요청이 감소되어 서버 부담이 줄어듬
- Task Queue에서 Timer나 Promise도 일시 정지되었다가, 복원시 이어서 실행 (=> 즉, 작업들이 모두 보존되었다가 다시 처리)
- 뒤로 앞으로 이동 시 복원 (폼 입력이나 스크롤 위치 등도 복원됨)
- History.scrollRestoration을 통해 복원해주지 않아도 기억되어있음
2. 브라우저 수준 캐싱
- HTTP 캐싱(브라우저 캐시)와 다르게 네트워크 요청 없이 메모리에서 페이지를 즉시 복원
- 스크롤 위치와 필터 상태가 그대로 유지
활성화 확인
1. 브라우저 개발자 도구에서 Network > Disable cache 체크 해제 확인

2. Performance 탭 / Network 탭(-> 네트워크 요청 발생 x)
뒤로가기 > 앞으로 가기 시에 캐시 테스트 데모사이트
페이지 전환 스냅샷을 보고 Event log에서 아래와 같이 확인 가능하다.

Javascript 로 확인
- event.persisted === true이면 페이지가 Bfcache에서 복원된 것.
- pageshow, pagehide 이벤트를 통해 Bfcache를 관찰할 수 있지만, 페이지가 Bfcache에 의해 복원되었는지 여부는 정확히 알수있지만, 페이지 이동시에는 현재 페이지를 캐시 하려고 했다는 사실만 알 수 있다고 한다.
window.addEventListener("pageshow", (event) => {
if (event.persisted) {
console.log("Page was loaded from Bfcache");
} else {
console.log("Page was loaded normally");
}
});

Bfcache와 일반 브라우저 캐시, 같은거 아냐 ??
- 브라우저캐시는 정적리소스(HTML, CSS, JS)를 캐싱하는데, Bfcache는 DOM 상태나 Javascript 메모리, 스크롤 위치에 대해 캐싱한다.
- 또한 Bfcache는 즉시 로드이므로 지연을 느끼기 어려운데 반해, 브라우저캐시는 네트워크 요청이 필요한 경우에 따라 지연이 발생할 수 있다.
- 브라우저 캐시는 HTTP 캐싱 규칙에 따라 작동한다.
- Bfcache는 특정 조건을 충족해야 활성화된다..
Bfcache... 제약 조건이 있다.
페이지가 완전히 캐싱될 수 있는 경우만 동작하고 이 조건에 해당하지 않으면 데이터 요청&렌더링은 당연히 발생한다.
- 페이지에서 명시적으로 캐싱 비활성화
- 응답 헤더에 Cache-Control: no-store 또는 no-cache 포함할 경우
- 자바스크립트 코드에 unload, beforeunload 이벤트 리스너 등록한 경우
- 실제 페이지가 새로 로드되는 것이 아니므로 load 이벤트가 발생되지 않음
- PV 수집하는 경우 정확한 수집이 어렵다
- unload -> pagehide 사용
- 오픈된 네트워크 연결 정리 (WebSocket 또는 특정 네트워크 연결이 열려있을 경우)
- 페이지 이동 시 WebSocket이나 EventSource 연결을 닫아야 동작
- 일부 브라우저나 버전에서 Bfcache를 제한적으로 지원할 경우 (can i use에서 확인하기)
- 브라우저마다 캐시가 저장되는 시간도 다르다고 하는데, 크롬은 3분이지만 상황에 따라 유지되지 않을수도 있다고 한다.
- same-site 여부, 데스크톱/모바일 여부, https 적용 여부등에 따라서도 다른 동작할 수 있다고한다. (구체적인 조건/상황이 다름을 인지하기)
- 메모리가 부족한 경우
자 여기까지 개념을 익혔고,
사실 실무에서 고민하게 되었던 부분이 무한 스크롤링 패치에서 였다.
클라이언트 상태와 스크롤 위치가 초기화 되었는데, (useEffect로 데이터 초기화), 옵저버로 스크롤 이벤트 마다 데이터를 동적으로 가져와서 넣었기 때문에 데이터가 비어있는 상태에서 스크롤 위치가 복구되지 않는 부분이 문제였다.
초반의 서버사이드 패치로 데이터를 넣은 부분은 뒤로가기 시 다시 요청하지 않으므로, 딱 거기까지 스크롤이 복구되었다.
(스크롤 위치와 데이터 간 불일치)
그래서 데이터를 세션스토리지에 담고, 접근 시 복원하는 작업을 진행했다.
(이때 timestamp를 넣어줘서, 세션이어도 만료시간을 지정해주고 특정 시간이 지나면 최신화를 위해 리프레시가 발생하도록 유도했다)
-> 이렇게 하니 스크롤 위치가 복원되어 따로 스크롤 복원을 진행하지 않았다.
리스트를 그리고 뒤로가기/ 앞으로가기를 하면서 모든 페이지에서 이러한 방법을 채택한 것은 아니었지만(리소스에 따른 우선순위) 사용자 경험은 역시 재미있는 작업인 것 같다.
'개념' 카테고리의 다른 글
| 원링크 (One Link), 딥 링크(Deep Link), 디퍼드 딥 링크 (Deferred Deep Link) - 웹뷰와의 통신 (0) | 2024.12.02 |
|---|---|
| 04. 호이스팅(Hoisting)에 대해 간단히 설명해주세요 (0) | 2022.09.11 |
| 03. 실행 컨텍스트(Execution Context)에 대해 설명해주세요. (0) | 2022.09.11 |
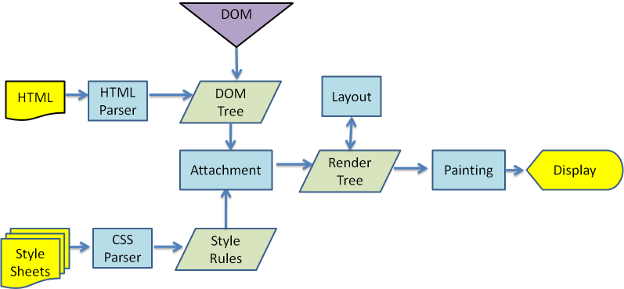
| 02. 홈페이지가 사용자에게 웹 사이트를 보여주는 과정을 간략히 설명해주세요. (브라우저 렌더링 포함) (0) | 2022.09.07 |
| 01. 브라우저 구조에 대해 간략히 설명해주세요. (0) | 2022.09.07 |
| URI? URL? 같은거 아니었어? 엥 URN은 또 뭐야? (0) | 2021.08.30 |
| 사용자 인증? 토큰? JWT(Json Web Token)란 뭘까? (0) | 2021.08.25 |
| [크롬 확장 프로그램 제작] 셋팅 방법 (0) | 2021.06.17 |