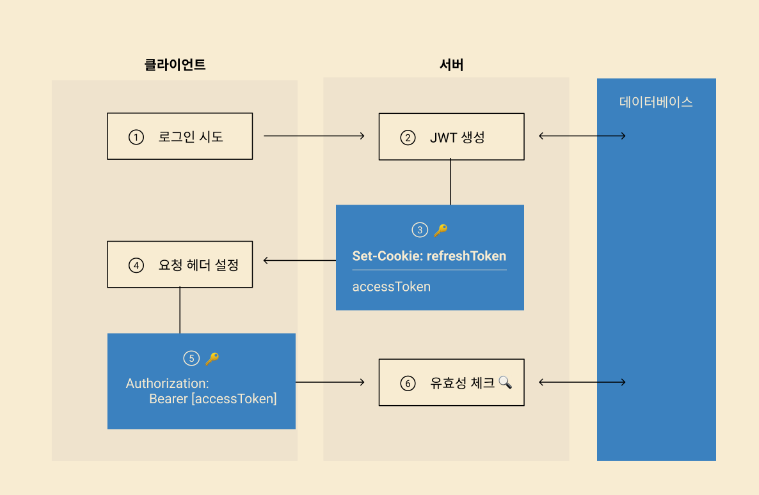
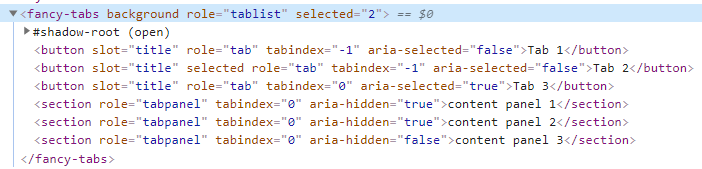
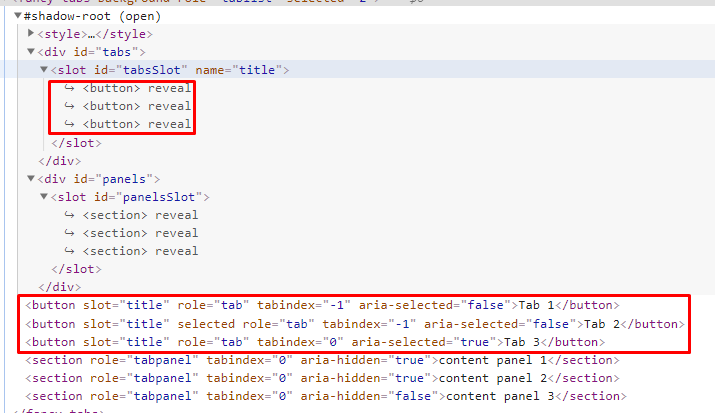
정책에서 그래프를 단순하게 가져간다고하고 하나의 티켓에 하나의 커밋을 하기로 했기 때문에 squash와 rebase를 해서 그래프를 단순하게 한다.
squash, rebase 작업 전 후 비교 그래프
출처 : 원본 글
작업 브랜치의 수명을 짧게 가져가는 것이 좋다.
항상 git-flow로 흘러간 것은 아니지만 시행착오를 겪으며 브랜츠 전략을 더더욱 견고히했다고 한다.
예전에 읽게된 글을 다시 읽게되었다. 회사에서 flow를 재 정의하게 되었는데, 글을 읽으며 재 정의된 회사 정책과 비교할 수 있는 기회였던 것 같다. 안쓰는 기능들도 있어서 반성을 하기도 하고.. 뱅크샐러드의 포스팅 '하루 1000번 배포하는 조직되기' 글과는 플로우 추구 방식이 반대이기도 하는 글이기도 해서 뱅샐의 글이 생각나면서 재미있었다. 브랜치 관리가 관건.. 혹시나 2017년 글이기때문에 배민에서 플로우를 변경하지는 않았을까해서 찾아봤는데, 이후의 포스팅 콘텐츠가 없는 것으로봐서 git-flow 정착 후의 변화는 없는것 같다. 좋은 결과가 이어지고있기 때문이겠지?
손실함수 정의, 모델 구조는 이해하지 못했다. 어렵다. 가볍게 읽는 글이기에 넘어가야겠다. (이해를 위해 오랜시간을 쏟아야할 것같기도하고..ㅠ)
학습과정은 재미있었다. 데이터의 불균형이 생기면 학습 시 편향될 수 있기에 구축된 데이터를 토대로 복제해 균형을 맞춰주더라.
원본 글 출처
성능 향상을 위해 데이터 정제, 전이 학습등을 거쳤다. 전이 학습에서 재밌고 대단한 점이 유사도를 산출하는 것이었는데, 어휘의 중복, 의미적 유사를 계산하여 학습한다. 정성적인 측면(의미 유사)에서 가설을 하나 세웠다고하는데, 생각해보면 나도 가설과 같이 행동할 때가 많다.
‘평균적으로, 같은 사용자가 비슷한 시기에 같은 섹션에서 작성한 두 댓글은 다른 사용자가 작성한 두 댓글보다 의미적으로(즉, 정성적으로) 유사하다.’
- 원본 글 출처
탐지 사례와 결과에서 어휘가 비슷해도 의미가 다른 댓글에 대한 클린봇 2.0에 대한 반응이 있다.
같은 텍스트가 포함되어있어도 의미가 악플인지 아닌지에 대한 결과인데, 신기하고 재밌는 결과이다.